
Le Stack Technologique - Partie 7
Pour héberger mon site, j’ai choisi d’utiliser S3 d’AWS. Ce service permet de stocker des fichiers et de les servir comme un site web le ferait. C’est une manière très pratique d’héberger un site web sans devoir prendre un hébergeur dédié pour ça.
Bien sûr, comme toujours, ça ne vient pas gratuitement. Et je n’entends pas par là le coût du service mais bien plutôt la partie technique à appréhender et maintenir. Il faut quelques connaissances et ce n’est pas 3-4 clics et puis s’en vont.
Warning
En écrivant cet article, je me suis rendu compte que la manière de me connecter pour publier mes fichiers sur S3 est une manière qui commence à être dépassée. Disons plutôt qu’il y a de nouvelles manières de faire qui sont beaucoup mieux.
J’ai gardé les informations de comment j’ai configuré au départ mon workflow de publication avec un user et une policy mais j’ai ajouté la nouvelle manière de configurer les choses via de la configuration OIDC (OpenID Connect).
Access key
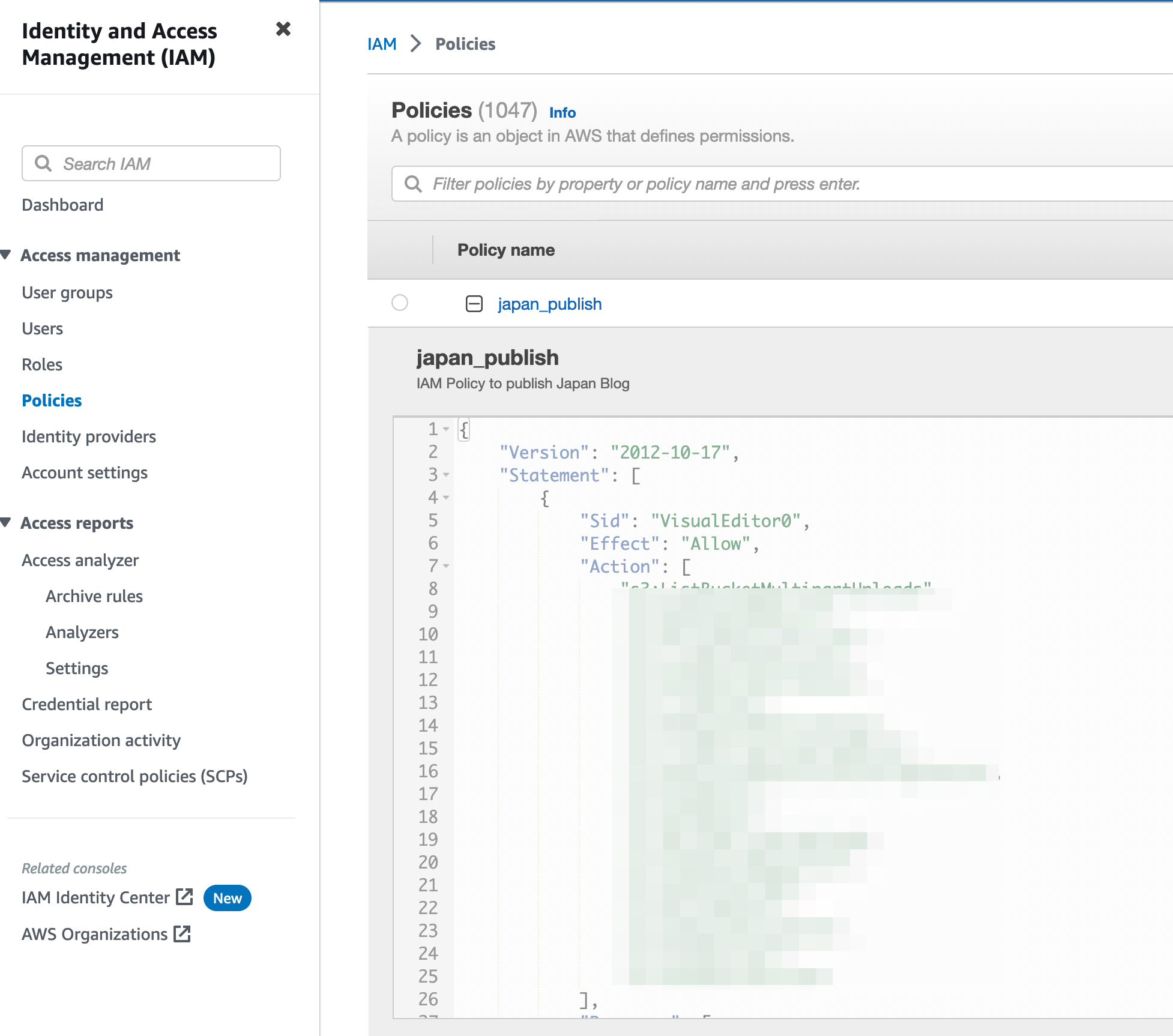
La première chose à faire c’est de configurer une IAM policy qui sera utilisé pour donner les droits à l’utilisateur
qui fera les uploads de fichiers. L’exemple suivant est un bout de la dite policy. En gros, cette policy donne les
droits suffisant pour que l’utilisateur puisse lire et modifier les objets dans le bucket S3.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:ListBucketMultipartUploads",
"s3:GetBucketWebsite",
"s3:ListBucketVersions",
"s3:GetObjectAttributes",
"s3:ListBucket",
…
],
"Resource": [
"arn:aws:s3:::japan.prevole.ch",
"arn:aws:s3:::japan.prevole.ch/*"
]
}
]
}
Une fois que la policy est créée, il faut créer un utilisateur. C’est ce qui est montré ci-après. On associe directement la policy qu’on a créé avant à cet utilisateur.
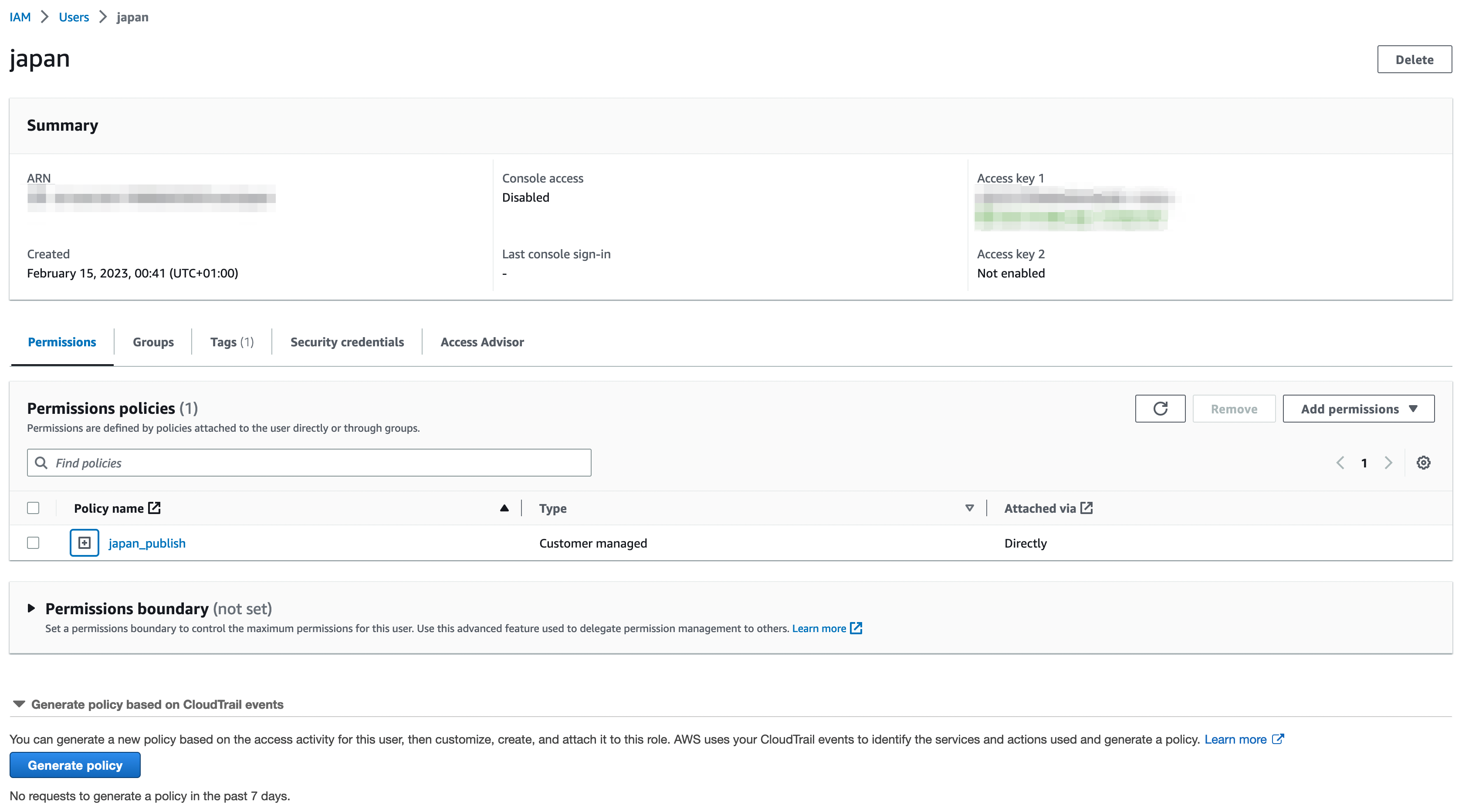
Il faut ensuite créer une clé d’accès qu’on va pouvoir utiliser dans mon workflow pour effectuer l’authentification auprès d’AWS pour pouvoir publier les fichiers sur S3. Pour se faire, il faut aller dans l’utilisateur et créer une clé.

On suit les instructions à l’écran qui nous montre bien que nous ne sommes pas entrain de suivre les meilleures pratiques. Vu mon use case, je ne pense pas que je prends un trop gros risque. Ensuite, on suit les écrans et on termine la création de la clé d’accès.
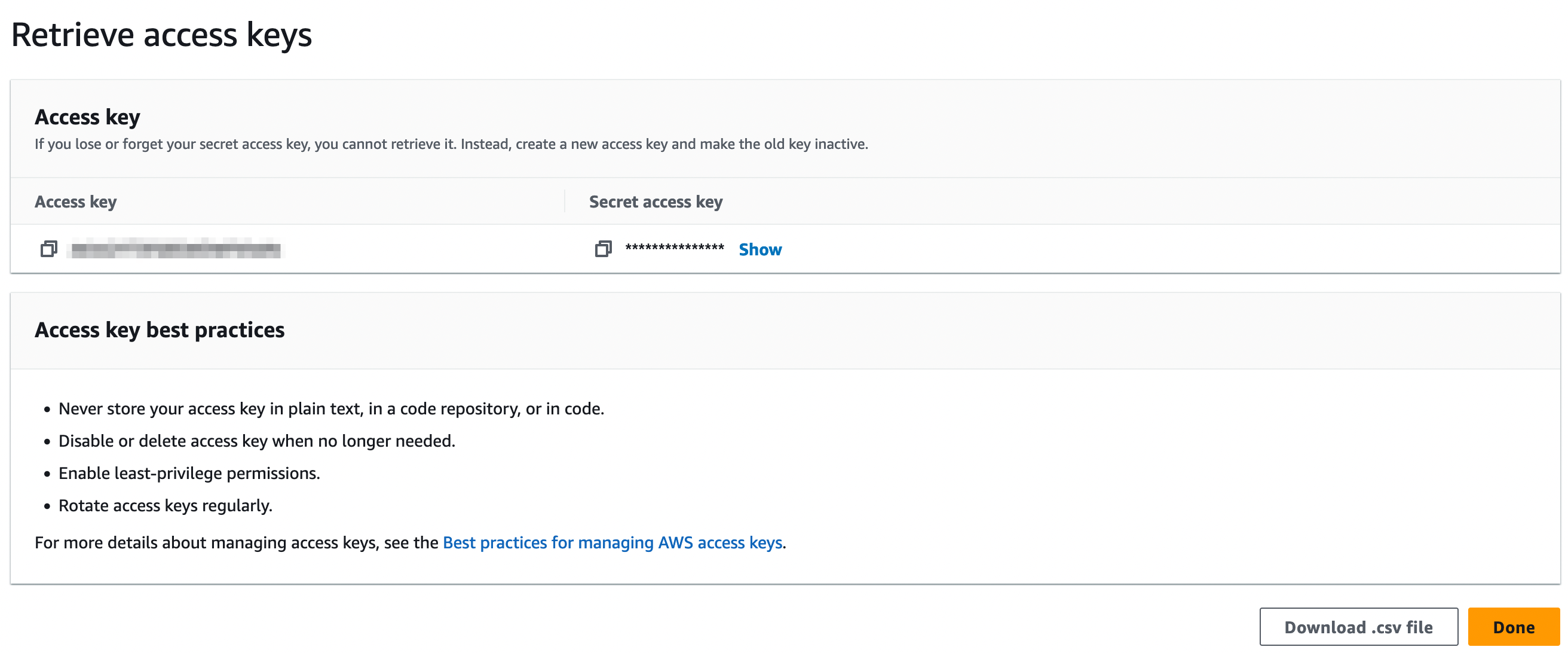
Dans le troisième écran, on récupère et stock précieusement les deux infos suivantes:
- L’access key
- La secret access key
C’est grâce à ces deux informations que nous pourrons nous connecter à notre bucket S3 et uploader nos fichiers.
GitHub Actions avec Access Key
Dans le cadre d’une utilisation des GitHub Actions pour publier mes fichiers, il suffit de configurer les quelques secrets dans les secrets du repository. Pour le workflow lui même, il est présenté dans sa forme Access Key dans l’article précédent.
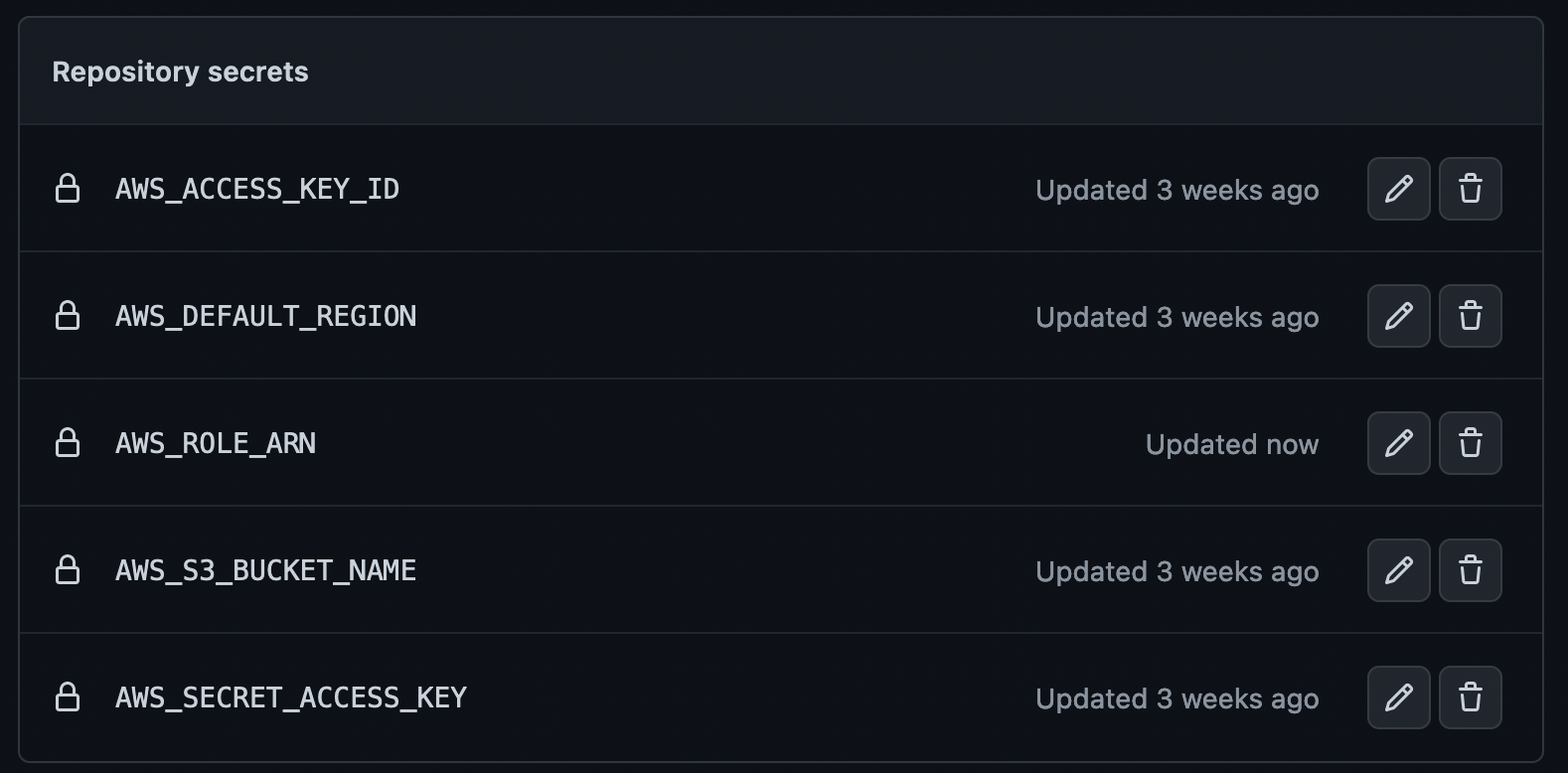
Les secrets sont les suivants:
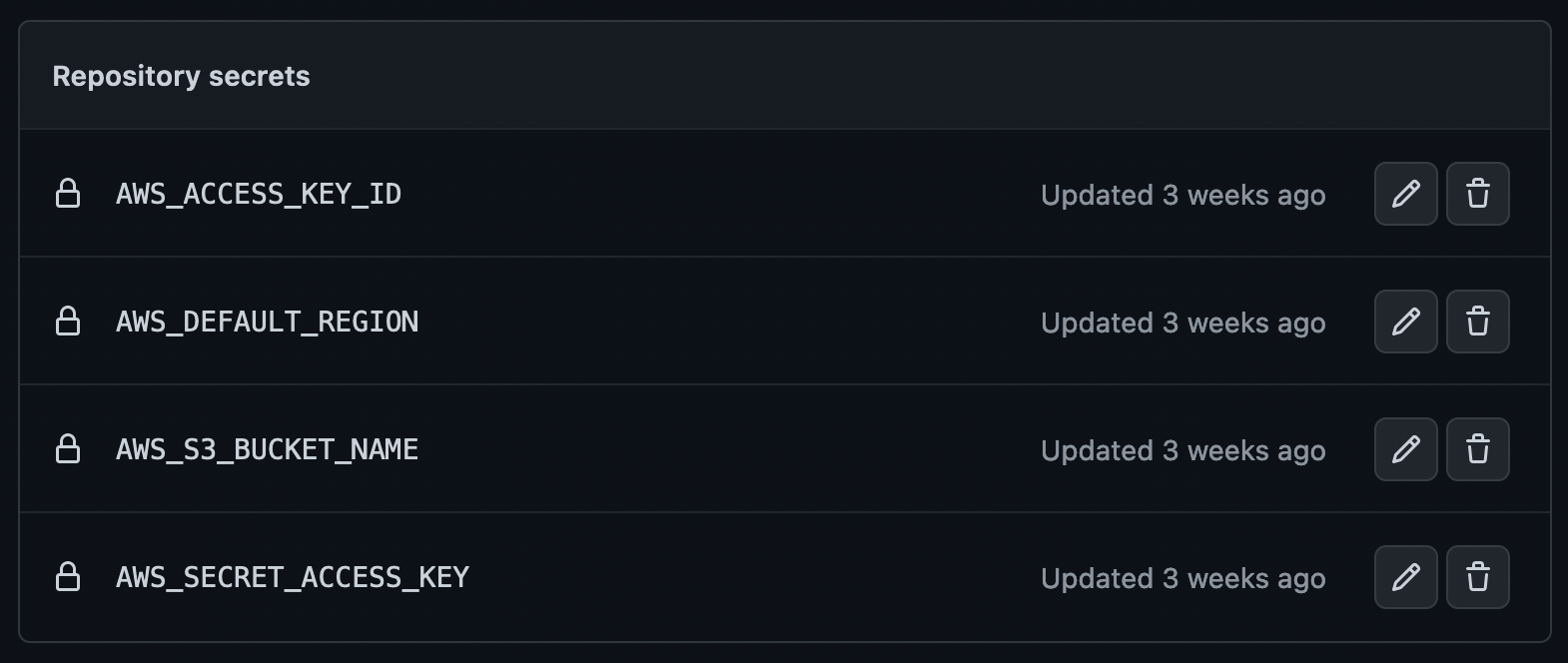
Rien de plus à configurer pour la partie des accès et de l’utilisation dans les workflows GitHub Actions.
OIDC - OpenID Connect
Comme mentionné, en cours d’écriture de cet article, je me suis rendu compte que je pouvais amélioré mon setup et mettre en place une connection via OIDC. Ça permet de mettre en place une manière de se connecter fiable sans stocker de secret du côté de l’appelant. C’est l’appelé qui s’occupe de vérifier que l’appelant est bien celui qu’il prétend être pour faire simple.
D’après la documentation de GitHub, la première chose à faire c’est de configurer un Identity Provider. Cette configuration se fait également dans le portail IAM d’AWS. Les informations de configuration sont données par GitHub sur leur page de doc.
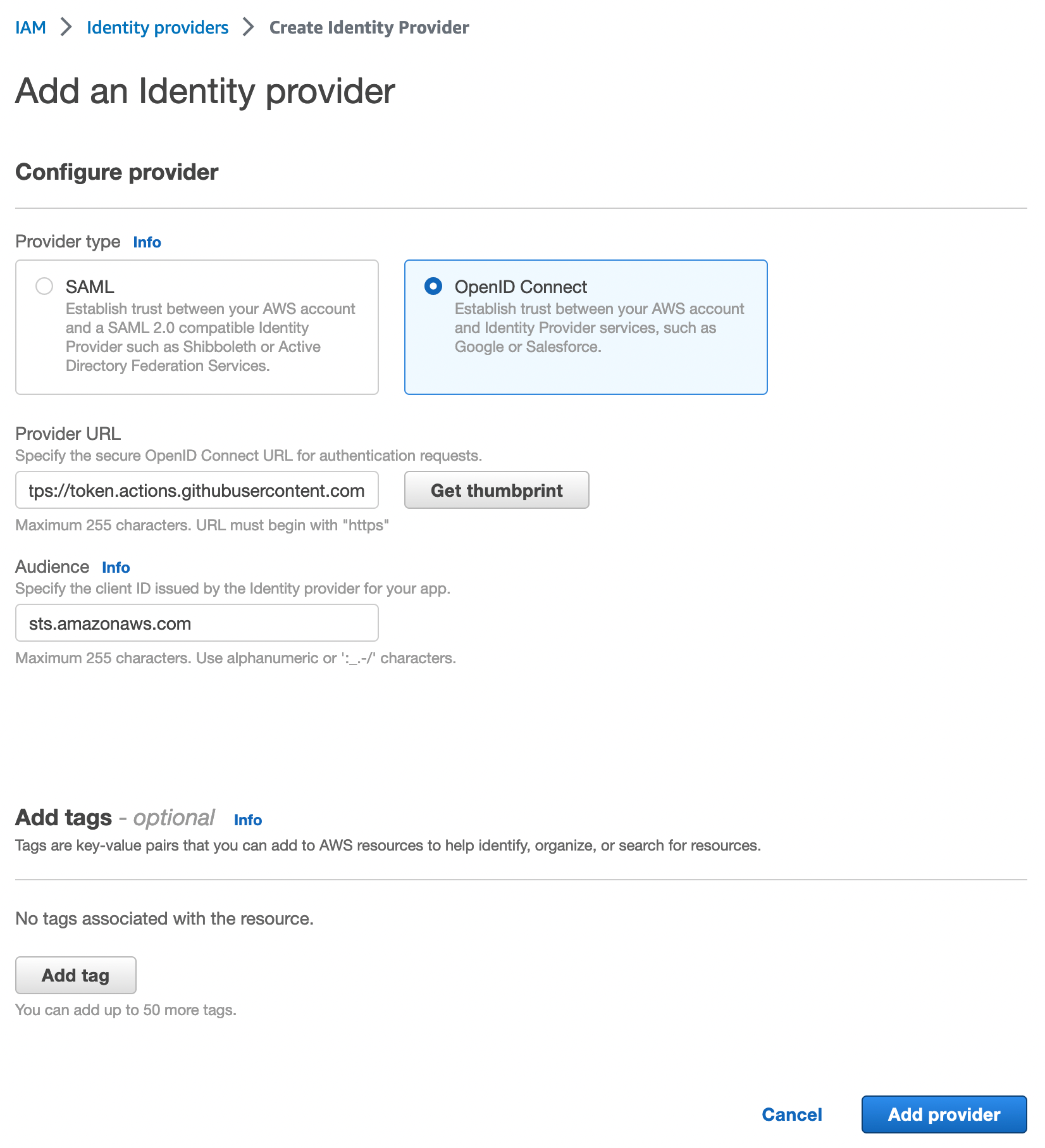
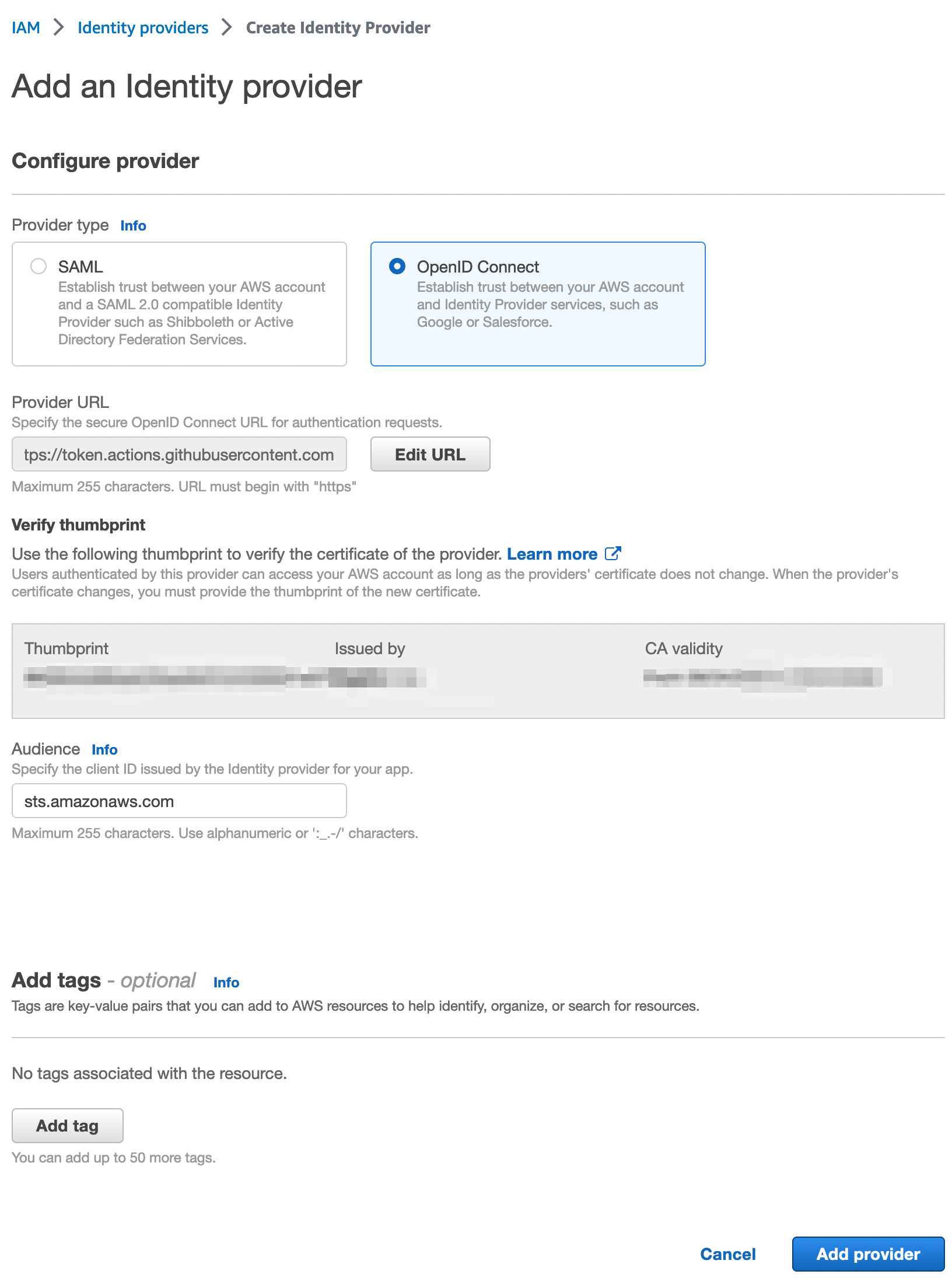
Une fois l’identity provider créé, il faut créer un rôle, pour se faire, c’est encore une fois dans le portail IAM que ça se passe. Il faut créer une custom trust policy.
Ensuite, il s’agit de configurer la trusted entity. C’est ce qui permet à l’appelé (AWS) de vérifier que l’appelant (GitHub Actions et plus spécifique mon repository) est bien ce à quoi on s’attend. Ça permettra ensuite d’associer les bons droits au token que GitHub Actions va recevoir pour effectuer ensuite les actions.
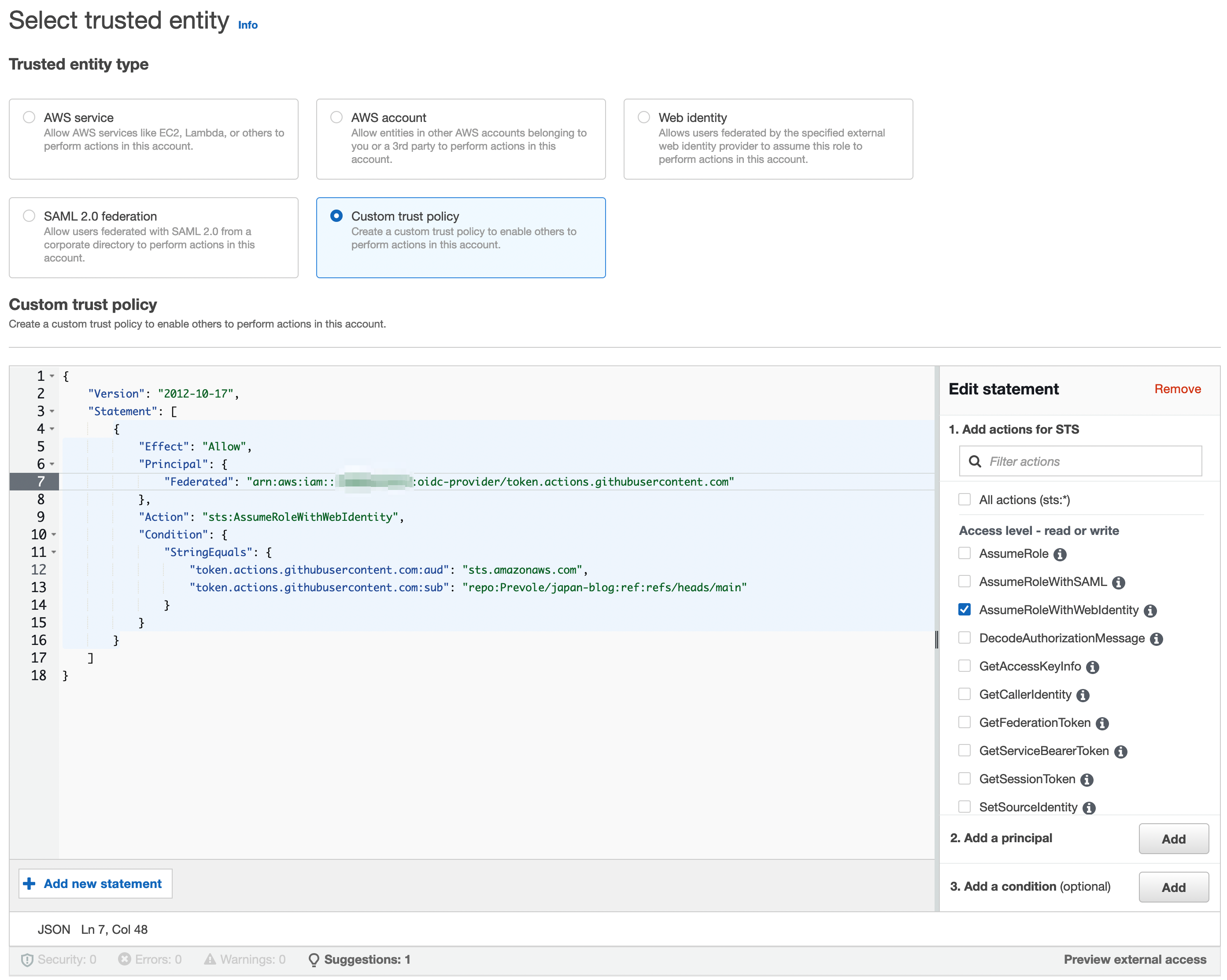
L’extrait de configuration json suivant est celui que j’ai préparé basé sur les exemples de GitHub et les spécificités que je souhaitais.
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::123…456:oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud":
"sts.amazonaws.com",
"token.actions.githubusercontent.com:sub":
"repo:octo-org/octo-repo:ref:refs/heads/main"
}
}
}]
}
Warning
Dans l’exemple précédent, il faut remplacer la chaine 123…456 par son account ID AWS. Il faut aussi remplacer
la partie qui configure l’accès au repository souhaité.
Bug
Il se trouve que pendant la rédaction de l’article, je n’avais pas encore testé le flot de déploiement. Une fois que
je suis arrivé à tester ma publication de mon site, je me suis rendu compte que le sub du trusted entity ne pouvait
pas fonctionner. Dans une autre page de doc de GitHub,
il est spécifié que la branche ne passe pas quand un workflow est associé à un environnement ce qui est mon cas.
A la place, il faut configurer quelque chose comme ça repo:octo-org/octo-repo:environment:production. Une fois cette
correction apportée du côté de la configuration IAM d’AWS, j’ai pu publié mon site sans problème avec la configuration
OIDC.
Sans cette modification, j’obtenais l’erreur suivante: Not authorized to perform sts:AssumeRoleWithWebIdentity
J’en ai profité pour faire ma première contribution à la
documentation de GitHub. On verra bien si c’est accepté ![]()
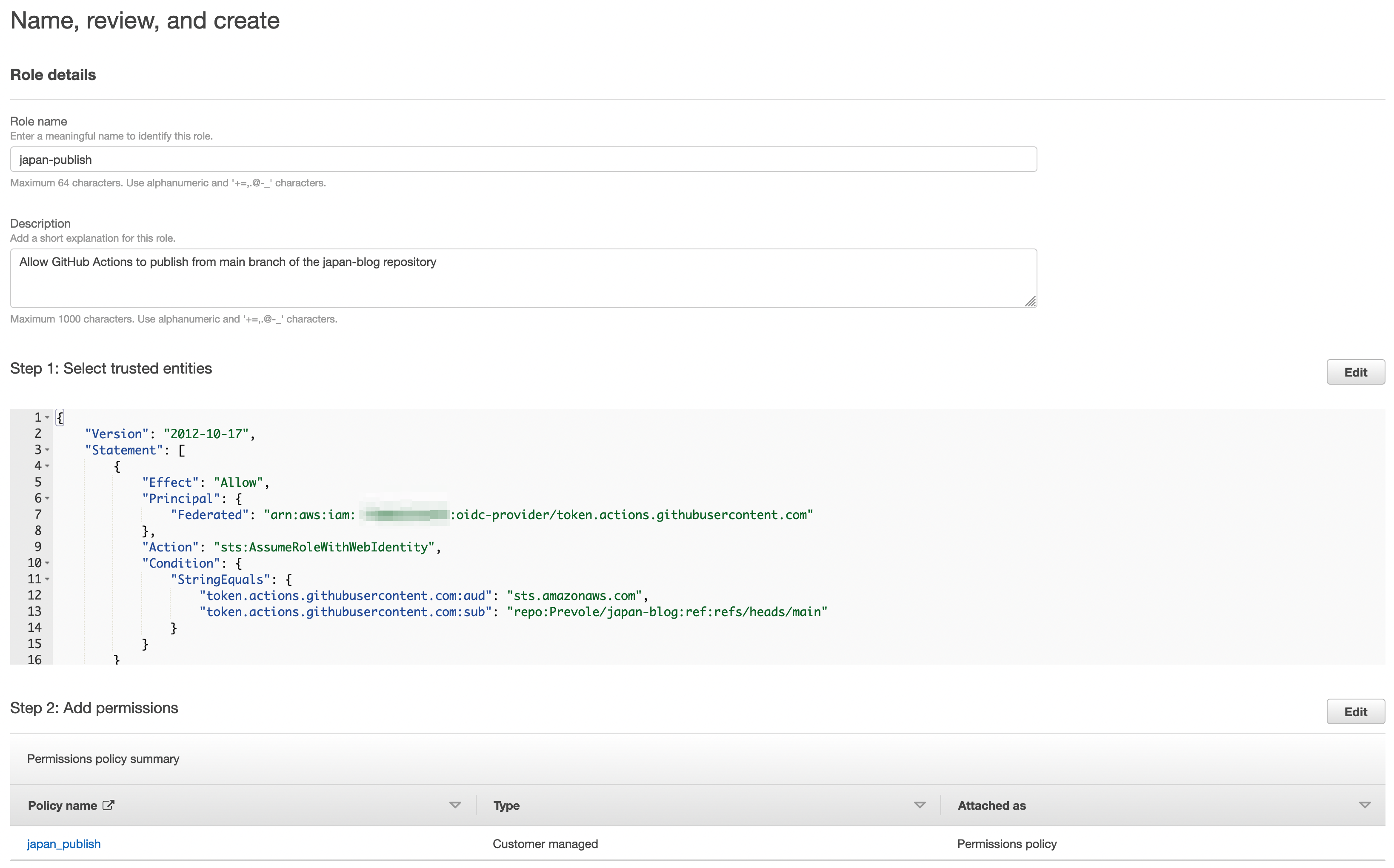
Dans l’écran suivant, on configure le rôle qui donne effectivement les droits au contexte de connexion. Et comme on a déjà préparé une policy qui fait exactement ce qu’on veut, et bien, on l’a réutilise.

Finalement, le dernier écran permet de configurer un nom et une description. Il permet également de revoir notre configuration dans son ensemble. Il ne reste plus qu’à cliquer sur create role pour finaliser la création.
La documentation GitHub nous explique qu’il faut que le workflow ou le job dispose de la permission id-token: write.
Vu que je n’ai qu’un job dans mon workflow publish, j’ai mis la permission au niveau du job et pas du workflow.
L’extrait ci-dessous vient de mon workflow.
jobs:
publish:
if: $
runs-on: ubuntu-latest
environment: production
permissions:
id-token: write
steps:
Et pour finir, il faut encore ajouter un nouveau step dans le workflow pour que l’authentification puisse se faire auto-magiquement. L’exemple suivant est directement repris depuis la documentation de GitHub.
- name: configure aws credentials
uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: arn:aws:iam::1234567890:role/example-role
role-session-name: github-actions-japan-blog-publish
aws-region: $
Tip
Pour l’info role-session-name, c’est un champ libre. Au moment où j’écris cet article, je ne sais pas encore à quoi
ça sert mais mon hypothèse est que ça doit aider à pouvoir différencier les sessions dans les logs sur AWS.
Pour retrouver l’information role-to-assume, il suffit d’aller dans la console IAM et chercher le rôle que nous avons
créé précédemment. Dans le rôle, on retrouve l’ARN du rôle qui nous permettra de configurer ce step.

Une fois l’ARN en main, il suffit de configurer le step correctement. Ne sachant pas trop à quel point cet ARN est une information sensible ou non, j’ai préféré la mettre en secret dans mon repository.
Info
Je n’ai pas encore supprimé mon access key de mes secrets. Je le ferai quand j’aurai fini de configurer la publication via l’OIDC. Au moment où j’écris ces lignes, la configuration n’est pas encore terminée.
Finalement, la configuration du step donne quelque chose comme ça dans mon workflow avec le step d’avant et le step d’après.
- name: Build Site
run: bundle exec jekyll build
env:
JEKYLL_ENV: production
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: $
role-session-name: github-actions-japan-blog-publish
aws-region: $
- name: Deploy to AWS S3
run: aws s3 sync ./_site/ s3://$ --delete --cache-control max-age=604800 --size-only
Et voilà, c’est terminé pour la partie de configuration de l’OIDC. Nous n’avons plus vraiment de secrets stockés dans GitHub Actions ce qui est un gain énorme. Devoir stocker des secrets, c’est toujours pénible.
AWS S3
A présent que les accès sont configurés, il faut préparer la configuration pour le bucket S3. C’est le service AWS qui va recevoir, héberger et servir les fichiers de mon site statique.
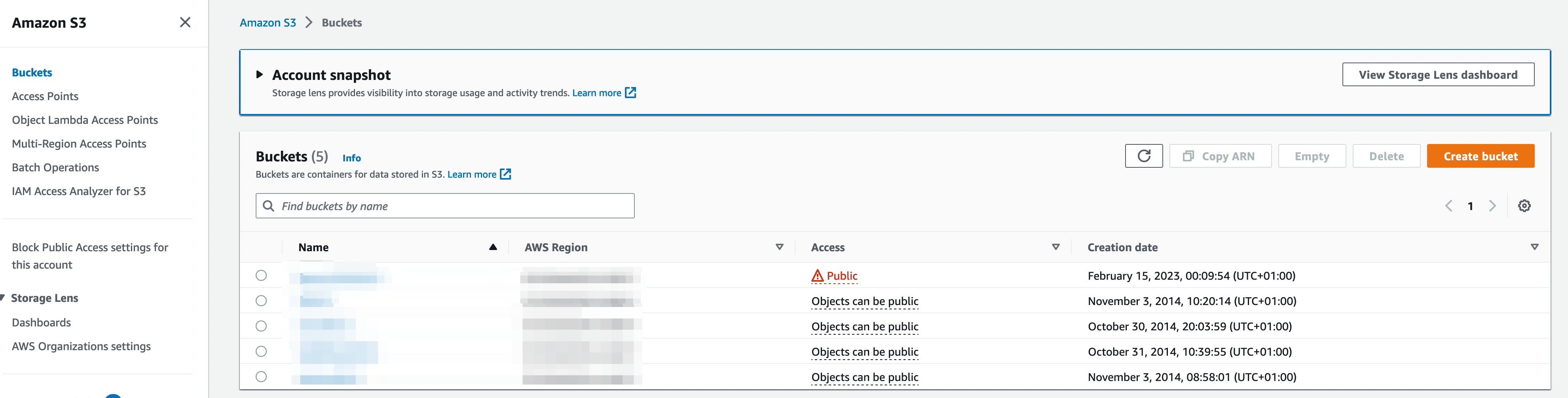
On commence par se rendre dans la console S3 pour voir la liste des buckets. Depuis cet écran, on peut créer un nouveau bucket.
Pour les options de configuration, je vous mets pêle-mêle les différentes sections de configuration pour le bucket S3. Il n’y a rien de particulier à cette étape de la configuration.

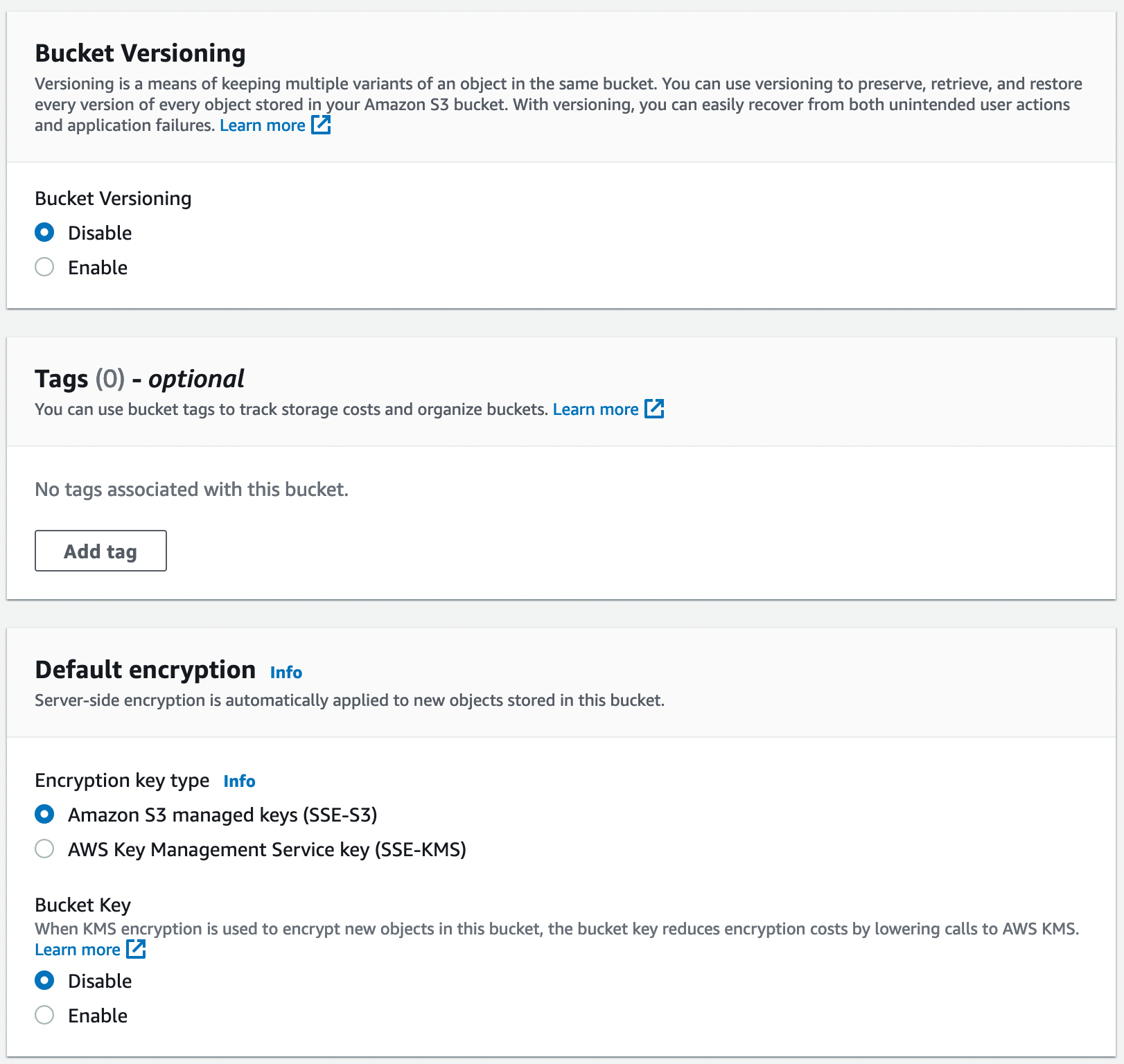
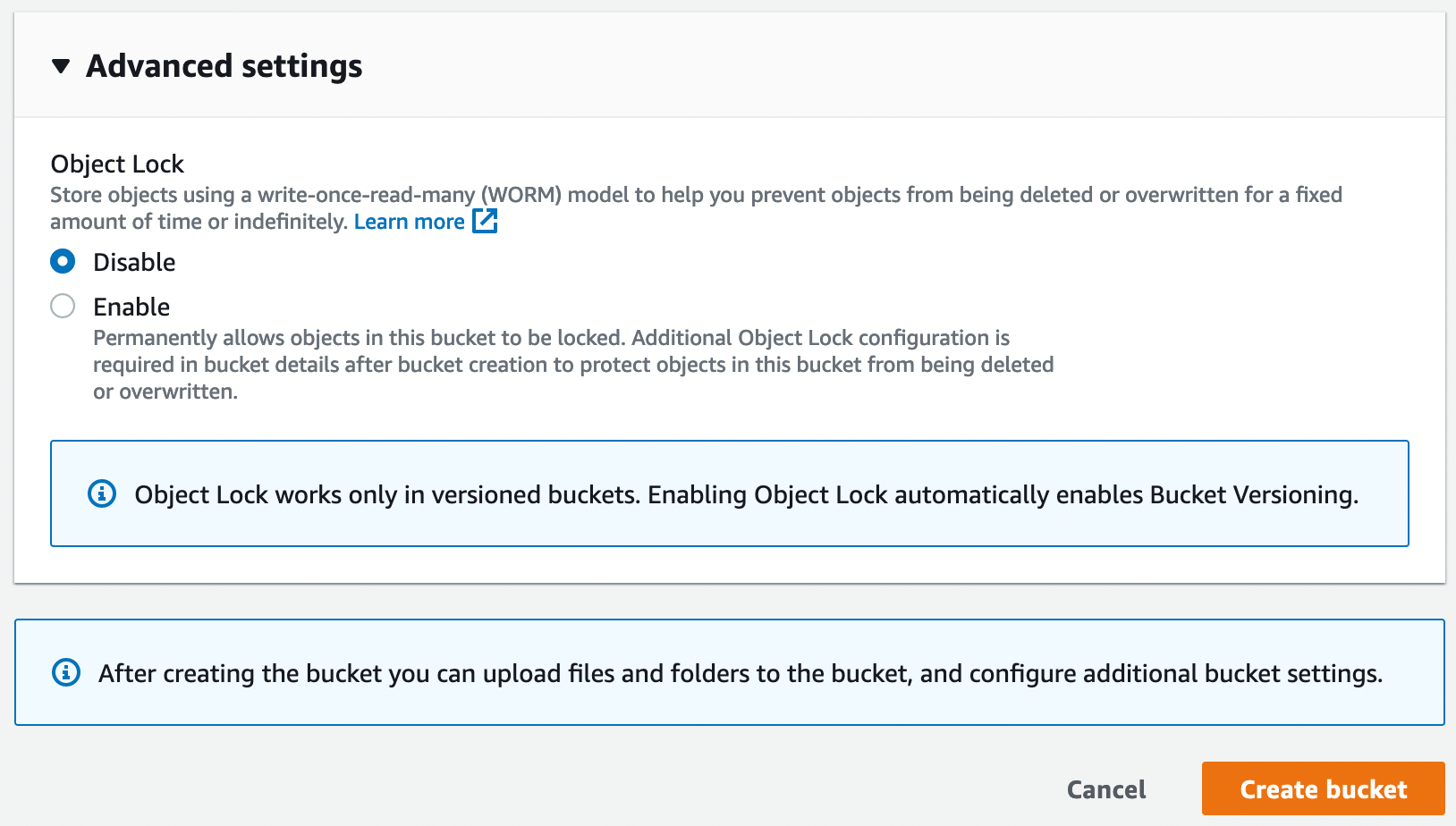
A présent, nous devant retourné dans le bucket pour configurer une ou deux choses afin d’ouvrir le bucket complètement et lui permettre de servir les fichiers comme un serveur web.
Nous devons configurer une bucket policy comme ci-dessous.
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::japan.prevole.ch/*"
}]
}
La configuration se trouve sous l’onglet permissions lorsqu’on édite un bucket.

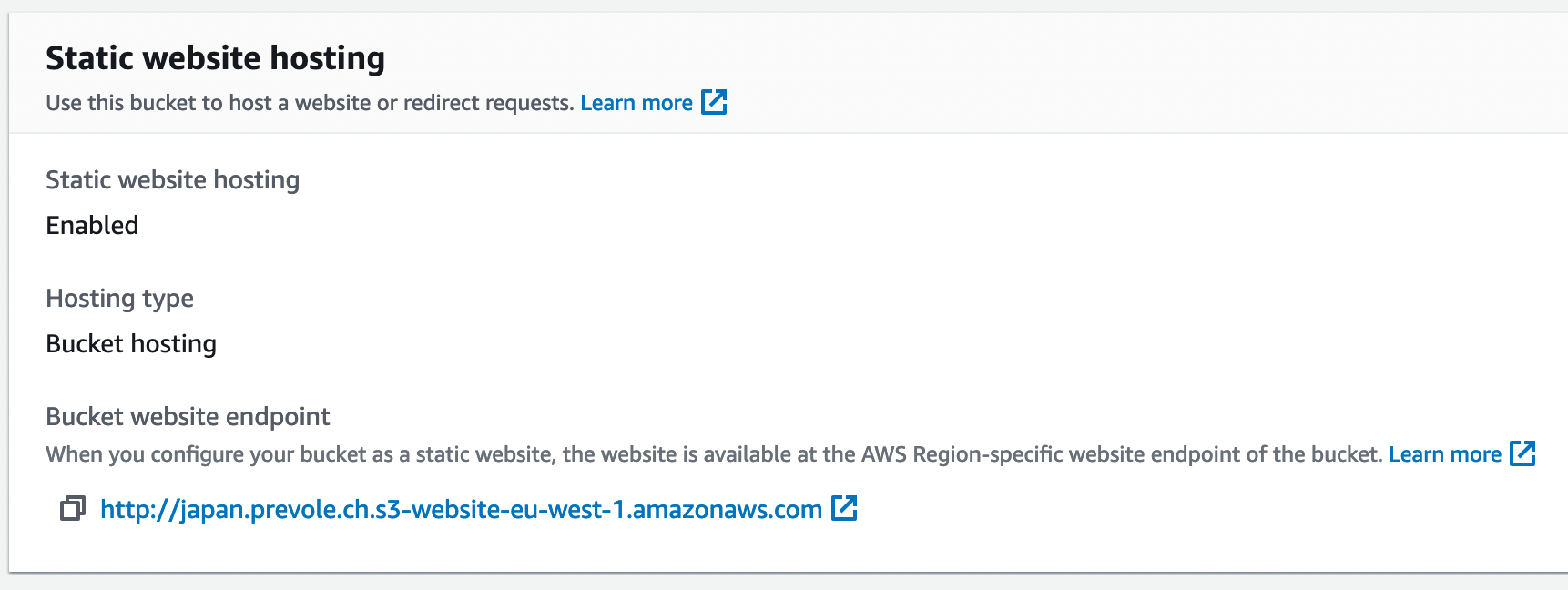
Ensuite, il faut configurer la partie qui expose le service sur Internet. Cette configuration se fait tout en bas de l’onglet properties.

On configure les deux trois options à disposition dont les pages d’erreurs et d’index. Sans cette configuration, il n’est pas possible d’activer la configuration.
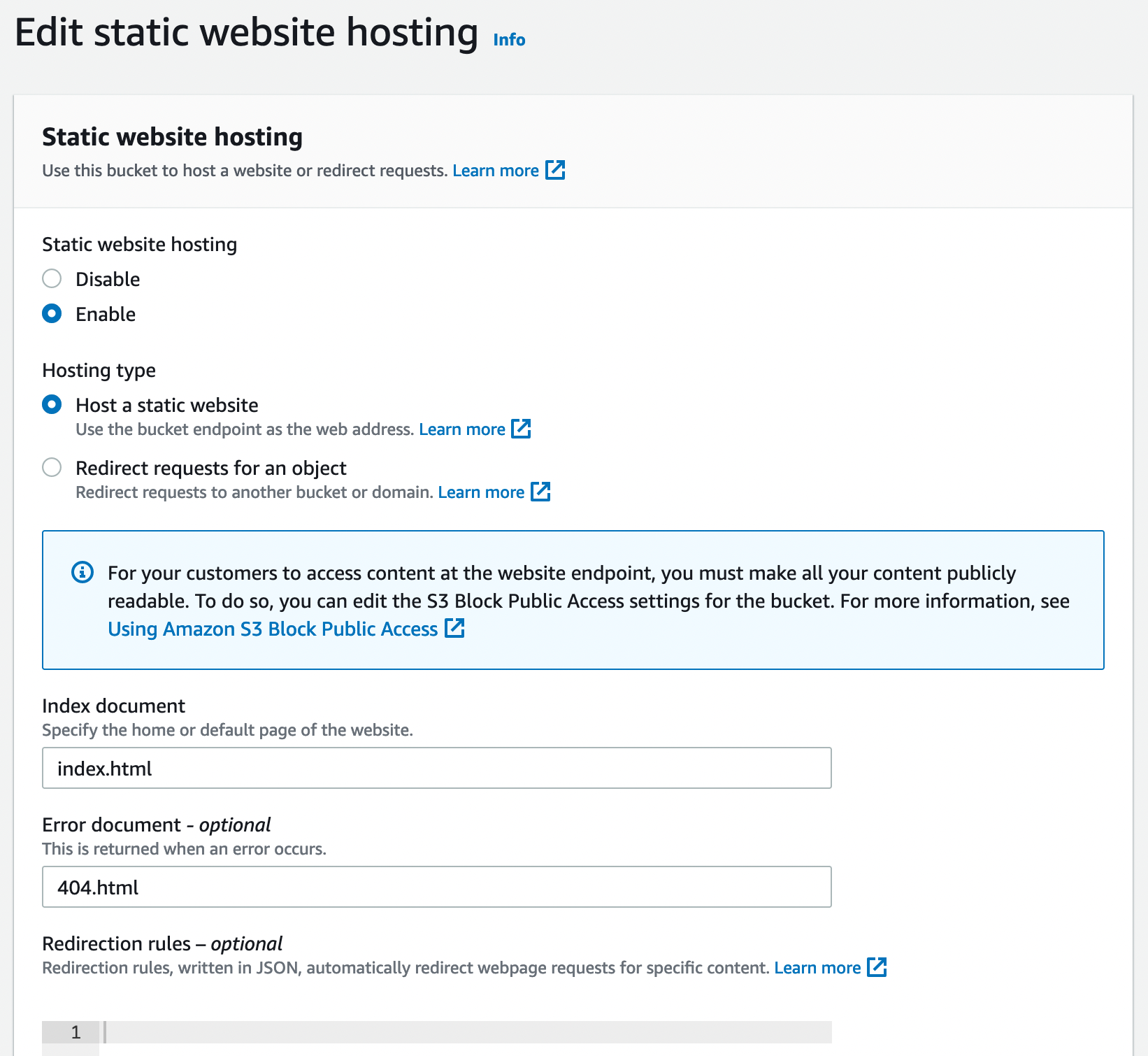
Pour se convaincre que ça fonctionne, il suffit de créer un petit fichier HTML avec un contenu comme celui ci-dessous par exemple.
Hello World!
Et de l’uploader à la main dans le bucket. Voici les écrans pour l’upload de fichiers. L’upload se fait depuis l’onglet objects du bucket.
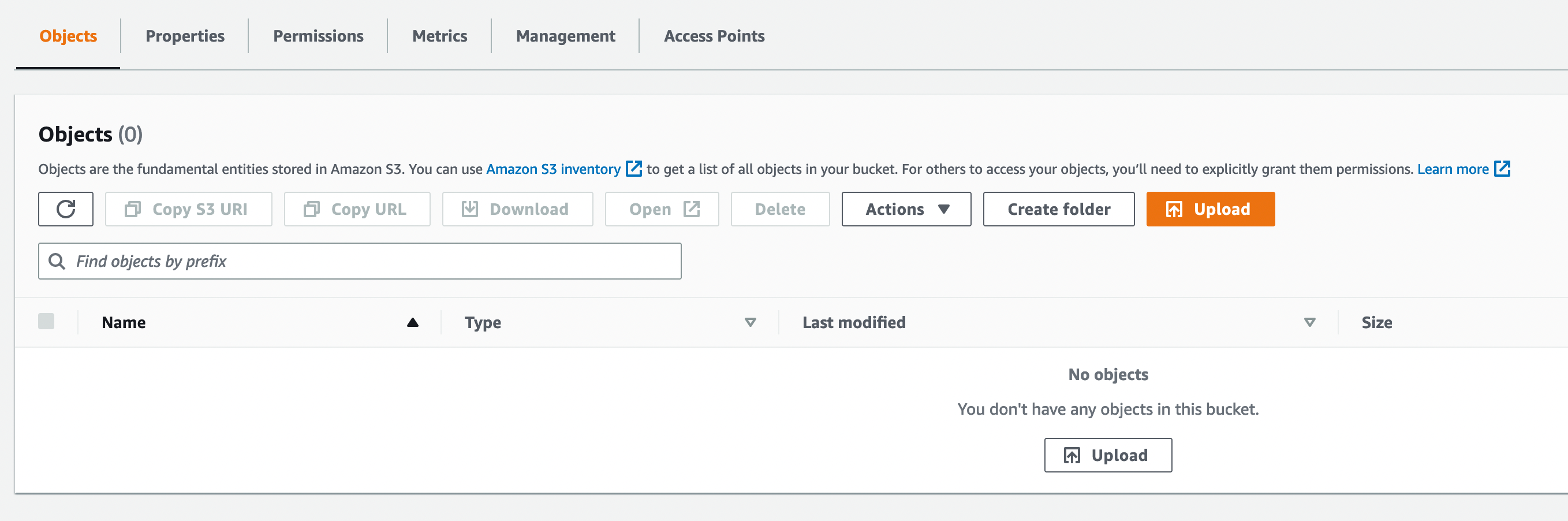
A partir de là, on est capable d’utiliser l’URL fournie par AWS pour voir si tout est bien configuré. On la retrouve au même endroit que la configuration du site statique. Elle apparaît après l’activation du site statique.
Conclusion
Et voilà, au terme de cet article, nous avons vu deux manières de configurer les accès et de les utiliser dans les workflows GitHub Actions. Mais surtout, nous avons vu comment configurer un Bucket S3 pour héberger un site web. C’est ce que j’utilise à présent pour héberger mon site statique du Japon.
Après avoir pushé mon article sur mon repository sur GitHub, le build s’est effectué et la publication a eu lieu avec la seconde technique d’authentification. J’ai un peu galéré à trouver le problème rencontré qui disait que je n’étais pas autorisé à faire l’opération. Après ce petit contre-temps, nickel-chrome, la publication fonctionne parfaitement bien.
Dans le prochain et dernier article de la série, nous allons voir comment configurer la partie DNS afin que mon ancien blog du Japon disparaisse au profit du nouveau.